试了试 KaiwuDB 3.1.0 的一键部署,可圈可点
最近听说 KWDB 3.1.0 版本的安装部署优化了,看了一下版本更新内容:

我记得上次安装 KWDB 2.1.0 的时候,费了不少功夫,安装依赖、手动配置、编译处理……零零碎碎折腾了小半天。这次看到 3.1.0 版本发布了一键部署脚本,忍不住想亲自体验一下,看看官方到底优化到了什么程度。
KWDB 是什么?
在开始之前,简单介绍一下 KWDB。KWDB 是 KaiwuDB 的简称,是一款面向物联网和工业互联网场景的分布式多模数据库。它同时支持时序数据和关系型数据的一体化存储与处理,既能高效处理设备产生的海量时序数据,也能管理设备元数据、业务信息等关系型数据。这种“一库多用”的特性,让它在智能工厂、能源管理、车联网等场景中越来越受欢迎。
KWDB 3.1.0 的官方文档地址:
https://www.kaiwudb.com/kaiwudb_docs/#/oss_v3.1.0/quickstart/overview.html
我这里选择社区版-快速部署:
点进去发现,3.1.0 版本发行包中,官方提供了一个自动化部署工具——快速部署脚本 quick_deploy.sh。
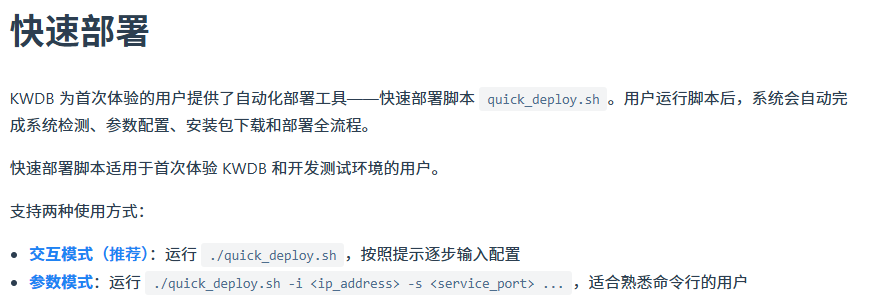
按照文档的说法,用户运行脚本后,系统会自动完成系统检测、参数配置、安装包下载和部署全流程。也就是说,理想情况下,一行命令就能搞定 KWDB 的安装。
下载脚本后,我习惯性地打开看了下。脚本内容不是很长,只有 234 行,但逻辑相当清晰。开头就限制了只能使用 root 用户执行,这可能是为了方便后续的系统配置(比如创建用户、设置目录权限等)。脚本支持的裸机部署操作系统目前仅限 Ubuntu 20.04/22.04 和 Kylin V10 SP3。大致流程如下:
脚本先强制 root → 解析参数/交互采集 → 校验 → 识别系统决定下载哪种发行包 → 从 gitee release 下载 tar.gz → 解包到 /tmp → 生成 deploy.cfg → exec 调用 deploy.sh 做单机安装。
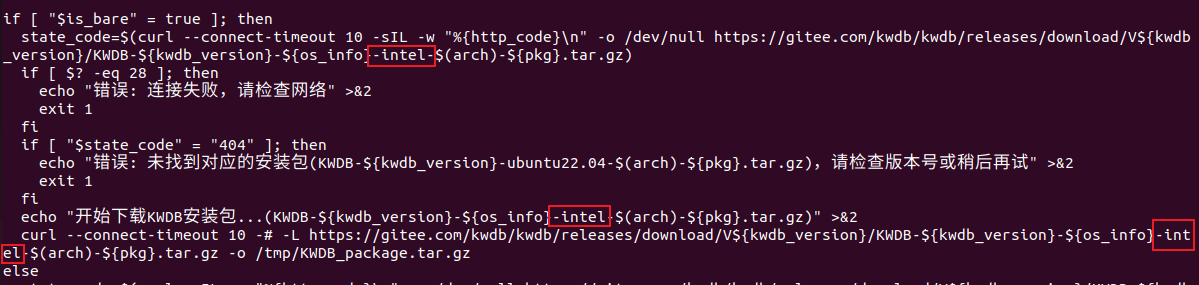
这里有一个关键点:脚本通过识别操作系统版本来决定下载哪个发行包。比如 Ubuntu 会下载 kwdb-community-{version}-linux-amd64.tar.gz,而 Kylin 会下载 kwdb-community-{version}-linux-arm64.tar.gz 之类的。但问题来了——虽然脚本中写了支持麒麟 V10 SP3,可是目前 KWDB 3.1.0 的官方发行版安装包还没有专门为 Kylin 编译的版本,所以 3.1.0 使用 quick_deploy.sh 实际上只能部署在 Ubuntu 上。这一点官方文档应该明确提示,避免用户走弯路。
操作系统安装就不做介绍了,装好 Ubuntu 22.04 之后,下面开始演示一键安装 KWDB 3.1.0。
首先,下载 quick_deploy.sh 脚本并赋予执行权限,然后执行安装:
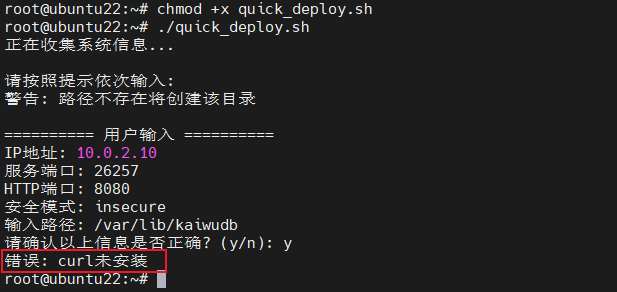
脚本提示需要先安装 curl,因为要通过 curl 从 gitee 下载安装包。这是一个很贴心的检查,不过如果能自动安装缺失的工具就更好了(当然,自动安装可能需要用户确认,避免未经许可修改系统)。
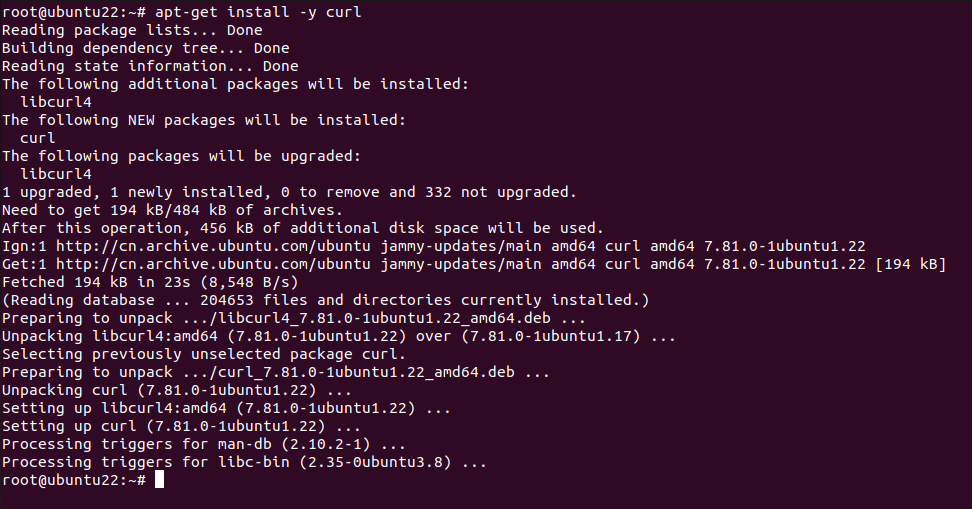
安装 curl 之后继续:
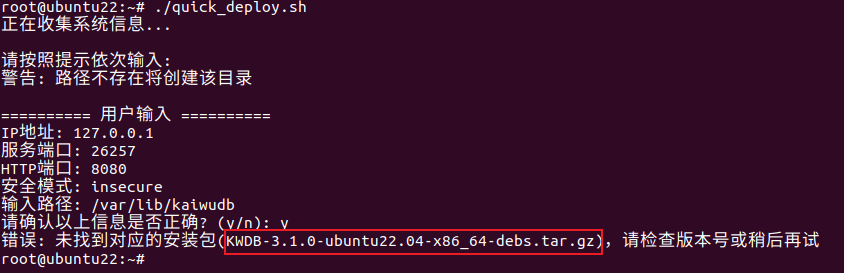
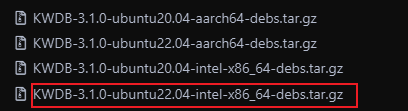
脚本尝试下载 kwdb-3.1.0-linux-amd64.tar.gz,但是返回 404。查看 gitee 上 KWDB 的 releases 页面,发现实际的包名是 KWDB-3.1.0-ubuntu22.04-intel-x86_64-debs.tar.gz,多了 “intel-“ 字样,看来是脚本中的包名模板没有及时更新。
既然知道了问题,直接修改脚本,包名加上 “intel-“:
再次执行安装:
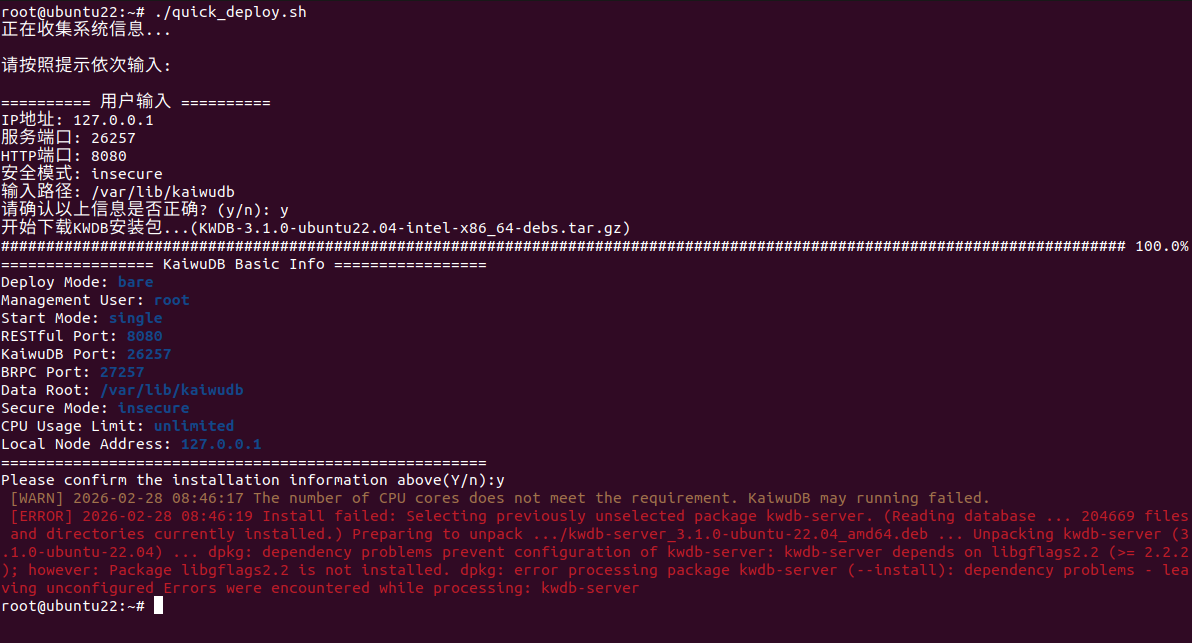
这次脚本成功下载了安装包,但在解压后的依赖检查阶段报错:缺少 libgflags.so.2.2。这说明脚本虽然下载了 KWDB 的二进制包,却没有检查系统是否满足运行时依赖。对于 Ubuntu 系统,需要安装 libgflags-dev 或者 libgflags2.2。

手动安装依赖 libgflags2.2:
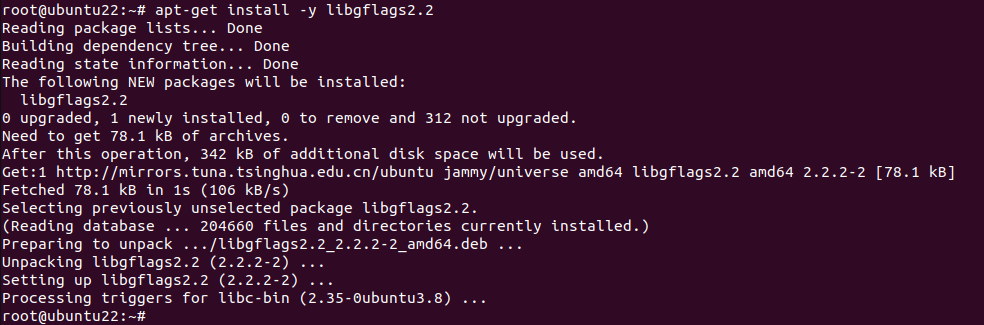
安装 libgflags2.2 后再次执行:
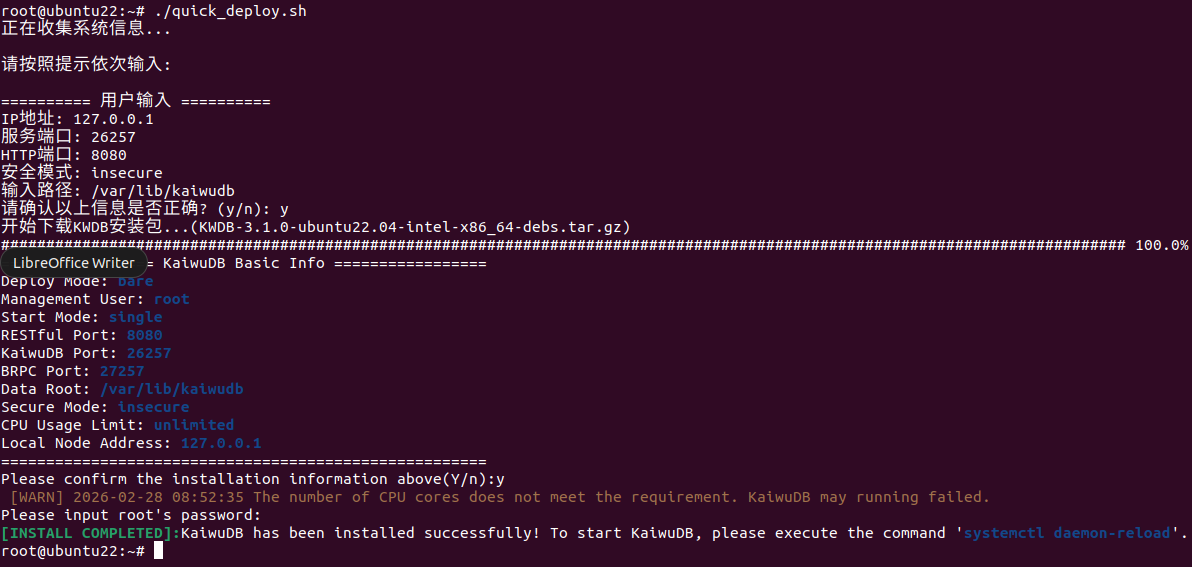
这次顺利通过了依赖检查,脚本自动执行了 deploy.sh,进行用户创建、目录初始化、配置文件生成、服务启动等操作,最后输出安装成功的提示。
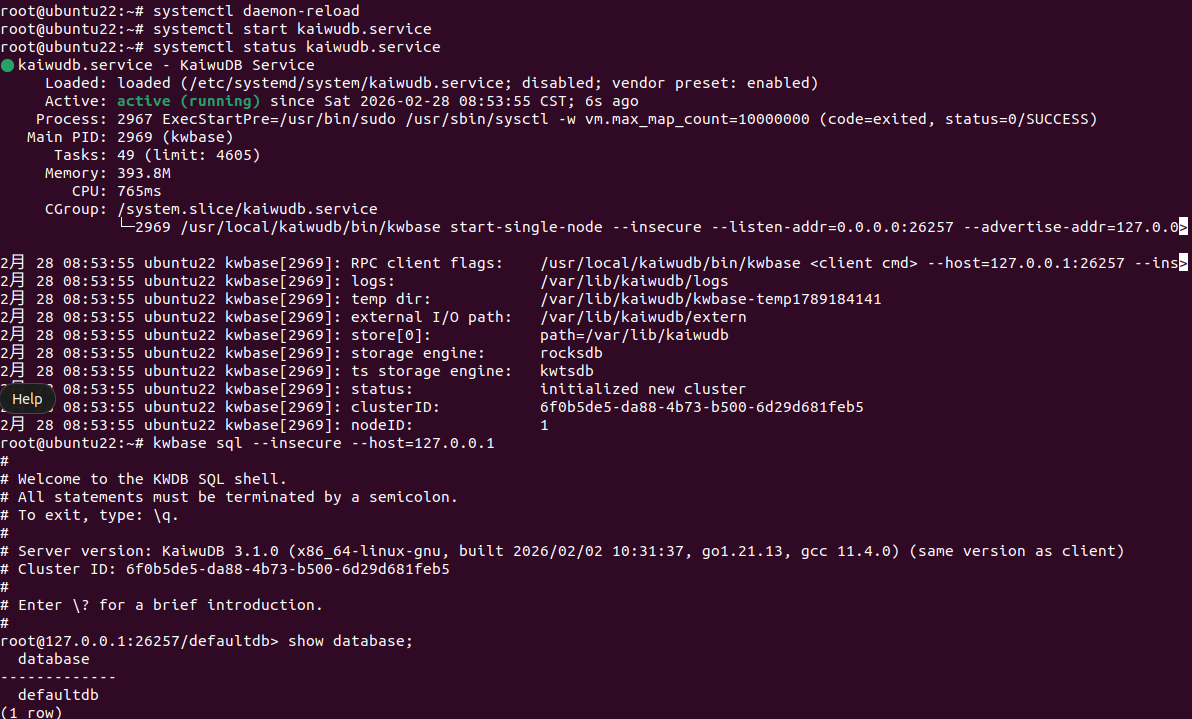
安装完成后,我们可以快速验证一下数据库是否正常。
通过这次实际体验,KWDB 3.1.0 的一键部署脚本确实大大简化了安装流程,从原来需要手动配置多个步骤到现在基本上能自动完成。但过程中也暴露出几个可以改进的地方:
- 脚本和发行版的包名称不匹配:由于包名写错,导致第一次运行时下载失败。建议官方统一发行版安装包的命名规范,并确保脚本中的名称与 release 中的实际名称一致。或者在脚本中添加一个 fallback 机制,当默认名称下载失败时尝试其他常见命名。
- 依赖检查不够完善:脚本在安装前只检查了 curl 等工具,但没有检查 KWDB 运行所需的系统库(如 libgflags)。建议在脚本的“系统检测”阶段增加对必要共享库的检查,并给出明确的安装命令(例如
apt-get install -y libgflags2.2),或者直接提示用户安装缺失的依赖包。这样能避免用户执行到一半才发现缺依赖。 - 支持的系统类型和版本有限:目前仅支持 Ubuntu 20.04/22.04 和 Kylin V10 SP3,且 Kylin 版本实际上还没有对应的安装包。对于使用 CentOS、Debian、openEuler 等其他 Linux 发行版的用户,仍然需要手动部署。希望官方能尽快适配更多主流操作系统,或者提供通用的二进制包,让用户自行解决依赖。
- 只支持联网下载安装包:脚本默认从 gitee 下载安装包,但很多生产环境是无法访问外网的。建议增加离线安装模式,允许用户预先下载好安装包,然后通过脚本参数指定本地路径进行安装。这样既适用于联网环境,也适用于内网环境。
- 缺乏详细的安装日志:脚本执行过程中虽然输出了一些信息,但不够详细。如果安装失败,用户很难定位具体是哪个步骤出错。建议增加详细的日志输出,并将日志保存到文件中,方便排查问题。
其实,现在很多数据库厂商都非常重视“首次安装体验”,因为这是用户接触产品的第一步。KWDB 作为一款新兴的国产数据库,在 3.1.0 版本中推出 quick_deploy.sh,是一个很好的开端。
未来,如果 KWDB 能进一步优化脚本,解决上述问题,相信会吸引更多开发者尝试和采用。毕竟,只有让用户轻松跨过安装这道门槛,才能让他们真正体验到 KWDB 在时序与关系数据一体化处理上的优势。
总的来说,这次一键部署的体验虽有波折,但整体还是感受到了官方的诚意。希望 KWDB 越来越好,国产数据库加油!