从 DBA 视角看 OceanBase seekdb
大家好,这里是公众号 DBA学习之路,分享一些学习数据库路上的知识和经验。

@TOC
前言
随着 AI 技术的快速发展,AI 应用的快速演进正悄然改变着数据架构的格局。传统的“事务数据库+向量数据库+检索引擎”拼凑方案,虽然能满足功能需求,却带来了显著的数据一致性问题与运维复杂性。

OceanBase 团队近期开源的seekdb,正是瞄准这一痛点,尝试从架构层面提供一体化解决方案。

seekdb 介绍
OceanBase seekdb(以下简称 seekdb)是一款AI 原生混合搜索数据库,基于 Apache 2.0 协议开源。其核心理念在于“AI Inside”,在一个数据库引擎内原生融合了向量、文本、JSON、时空等多模数据的存储、索引与检索能力,并内置了嵌入模型、推理等 AI 功能。

对 DBA 而言,seekdb 的核心价值在于 “简化” :
- 架构简化:将原先需要多套系统协同的 AI 数据栈,收敛到单一数据库内,消除了数据同步延迟与一致性问题。
- 运维简化:一套安装包、一种监控体系、统一的备份恢复策略,大幅降低了运维负担。
- 开发简化:提供标准的 SQL 接口和 AI Functions,支持从文档到向量数据的“Document-in / Data-out”端到端流程,减少了应用层大量的“胶水代码”。

安装部署
seekdb 延续了 OceanBase 在部署上的友好设计,提供多种方式,适应从开发测试到生产部署的不同场景。
部署前准备:
- 确保系统内核版本 ≥ 3.10.0。
- 预留至少 1 核 2GB 内存(用于基础测试),生产环境建议根据负载垂直扩展。
- 安装 MySQL 客户端或 OBClient。
本文分别演示其中三种安装方式。
yum 安装
本文采用 yum install 方式进行部署:
1 | ## 添加 seekdb 镜像源 |
源码编译
也可以使用源码编译:
1 | # Clone the repository |
rpm 安装
最简单的是用 rpm 进行安装:
1 | rpm -ivh seekdb-1.0.0.0-100000262025111218.el7.x86_64.rpm |
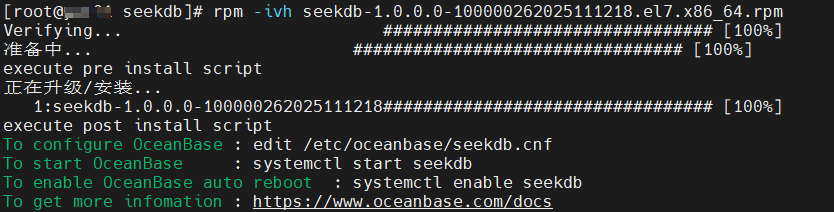
安装完成后,启动 seekdb:
1 | systemctl start seekdb |
安装 mysql8 客户端:
1 | rpm -e --nodeps $(rpm -qa | grep mariadb) |
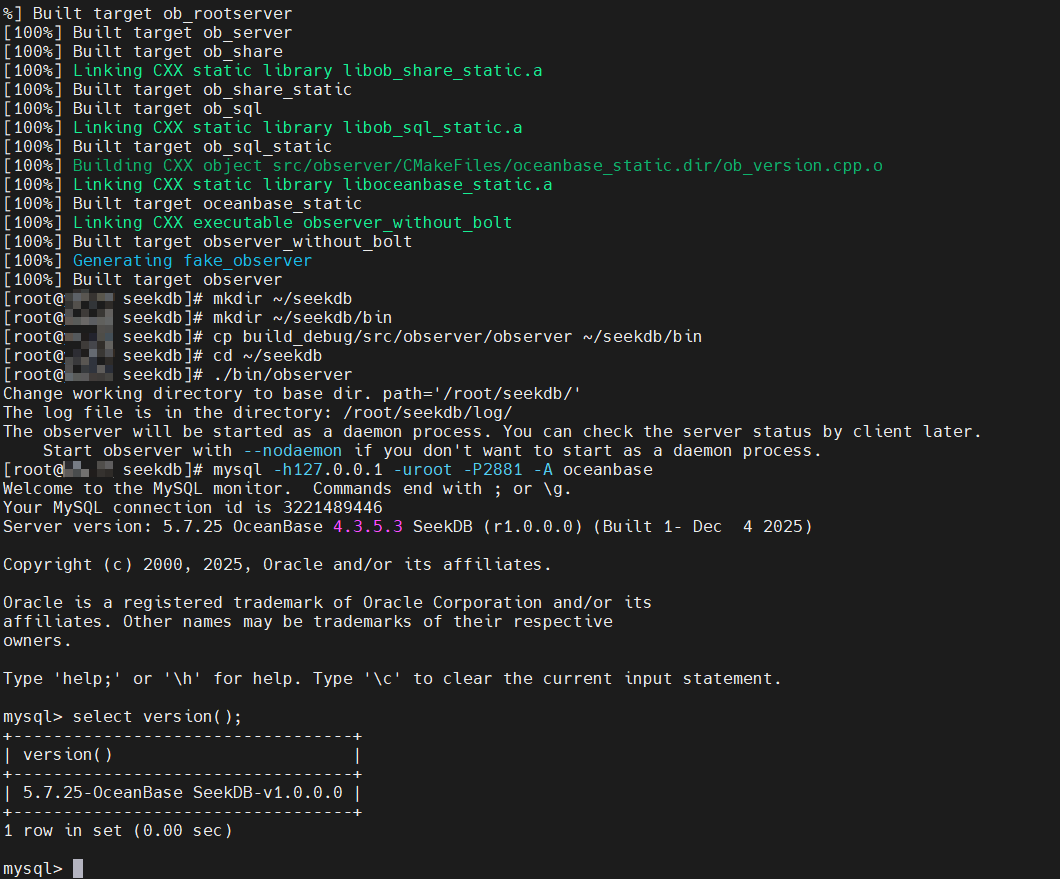
连接 seekdb:
1 | mysql -h127.0.0.1 -uroot -P2881 -A oceanbase |
或者安装 obclient:
1 | yum install -y obclient |
向量搜索
向量搜索是 AI 应用的基石,seekdb 使其变得像创建普通索引一样简单。
创建向量索引
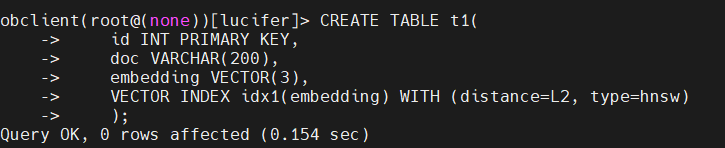
支持主流的 HNSW 索引,并指定相似度度量方式(如 L2 距离):
1 | obclient(root@(none))[lucifer]> CREATE TABLE t1( |
写入与混合查询
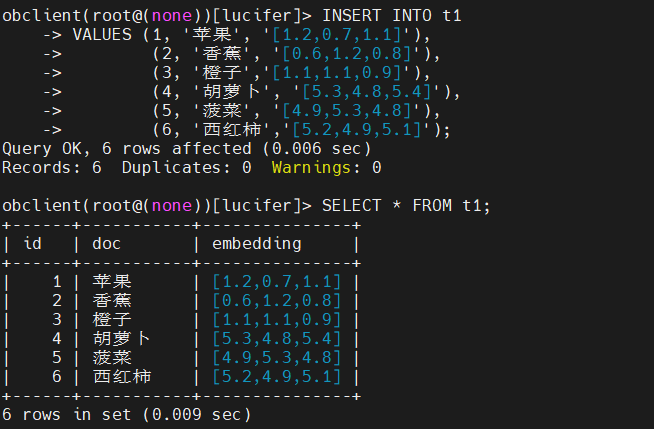
数据插入同时包含文本和其对应的向量(通常由外部 AI 模型生成):
将现实世界的对象(文字、图片、音频等)转换成数字数组表示:
- 文本 “苹果” → AI 模型 → 1.2, 0.7, 1.1
- 文本 “香蕉” → AI 模型 → [0.6, 1.2, 0.8]
- 文本 “胡萝卜” → AI 模型 → [5.3, 4.8, 5.4]
1 | obclient(root@(none))[lucifer]> INSERT INTO t1 |
语义相似的对象,向量在空间中的位置也相近。
执行向量搜索
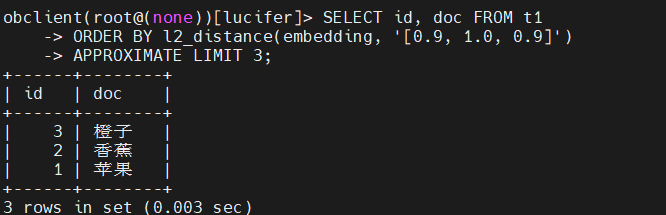
假设我们需要找到所有 ‘水果’,其对应的向量为 [0.9, 1.0, 0.9]:
1 | obclient(root@(none))[lucifer]> SELECT id, doc FROM t1 |
计算每个向量与查询向量的 L2 距离:
1 | 1. 苹果 [1.2, 0.7, 1.1] |
结论:水果类(苹果、香蕉、橙子)向量聚集在一起,与蔬菜类距离很远。
这条查询展示了 seekdb 的核心优势:在单条 SQL 中,同时完成了全文检索(LIKE)、向量相似度计算(l2_distance)和综合排序,无需在应用层合并多个系统的结果。
典型应用场景
构建企业知识库与问答系统(RAG)
传统方案需管理数据库、ES、向量库三份数据及其同步链路。seekdb 将知识文档的全文索引、向量索引统一存储和管理,利用内置的文本分割、向量化能力,简化了 RAG Pipeline 的构建,并确保了数据源的强一致性。
智能代码检索与管理平台(AI Coding)
代码的元数据(如函数名、语言)、依赖关系(图数据)、代码片段向量可统一存储在 seekdb 中。通过混合搜索,既能根据函数名精确查找,也能根据自然语言描述模糊匹配相似代码块,简化了开发资产管理。
AI Agent 记忆与状态管理
Agent 的对话历史、工具调用结果、用户偏好等结构化与非结构化记忆,可作为一个完整的会话上下文存入 seekdb。利用其向量和 JSON 查询能力,能高效实现“记忆”的检索与关联,支撑 Agent 的长期运行。
MySQL 应用的平滑 AI 化升级
对于已有 MySQL 业务,seekdb 提供了高度兼容的入口。可以在不改动过多业务逻辑的情况下,为特定表新增向量列和索引,逐步试点 AI 功能(如智能推荐、语义搜索),实现渐进式技术升级。
写在最后
OceanBase seekdb 的出现,代表了一种新的思路:将 AI 所需的数据处理能力深度集成到关系型数据库内核中。对于 DBA 和架构师而言,它的主要吸引力在于:
- 统一运维:一套系统替代多套异构数据栈,降低复杂度与成本。
- 数据强一致:向量、文本、关系数据在同一事务内更新,避免脏读。
- 标准接口:使用熟悉的 SQL 和扩展函数,降低开发团队学习成本。
- 渐进式升级:兼容 MySQL 生态,便于现有业务探索 AI 能力。
当然,作为一款新兴开源产品,其在超大规模向量集群管理、生态工具链成熟度方面仍有演进空间。但对于正在寻求简化 AI 数据架构的团队,seekdb 无疑提供了一个值得深入评估和试点的选项。它将数据库从“被动存储”的角色,转向为“主动赋能”AI 应用的智能数据平台。