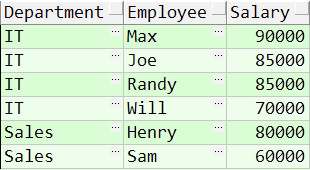
+------------+----------+--------+ | Department | Employee | Salary | +------------+----------+--------+ | IT | Max | 90000 | | IT | Randy | 85000 | | IT | Joe | 85000 | | IT | Will | 70000 | | Sales | Henry | 80000 | | Sales | Sam | 60000 | +------------+----------+--------+
解释:
IT 部门中,Max 获得了最高的工资,Randy 和 Joe 都拿到了第二高的工资,Will 的工资排第三。销售部门(Sales)只有两名员工,Henry 的工资最高,Sam 的工资排第二。
⭐️ 解题思路 ⭐️
为了更清晰的表达,我在本地测试环境构建测试环境数据。
构建测试数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
--create table CREATE TABLE employee (ID NUMBER,NAME VARCHAR2(20),salary NUMBER,departmentid NUMBER); CREATE TABLE department (ID NUMBER,NAME VARCHAR2(20)); --insert data INSERT INTO employee VALUES (1,'Joe',85000,1); INSERT INTO employee VALUES (2,'Henry',80000,2); INSERT INTO employee VALUES (3,'Sam',60000,2); INSERT INTO employee VALUES (4,'Max',90000,1); INSERT INTO employee VALUES (5,'Janet',69000,1); INSERT INTO employee VALUES (6,'Randy',85000,1); INSERT INTO employee VALUES (7,'Will',70000,1);
INSERT INTO department VALUES (1,'IT'); INSERT INTO department VALUES (2,'Sales'); commit;
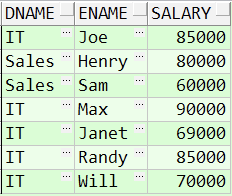
SELECT d.name dname, e.name AS ename, e.salary FROM employee e, department d WHERE e.departmentid = d.id
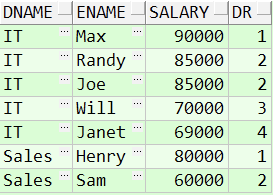
接下来,需要使用 dense_rank() 函数进行排序,并且将结果集进行分组:
1 2 3 4 5 6 7
SELECT d.name dname, e.name AS ename, e.salary, dense_rank() over(PARTITIONBY e.departmentid ORDERBY e.salary DESC) dr FROM employee e, department d WHERE e.departmentid = d.id
得到以上结果基本该题已经解出来了,最后只需要将结果取前三即可:
完整代码如下:
1 2 3 4 5 6 7 8 9 10 11
SELECT t.dname AS "Department", t.ename AS "Employee", t.salary AS "Salary" FROM (SELECT d.name dname, e.name AS ename, e.salary, dense_rank() over(PARTITIONBY e.departmentid ORDERBY e.salary DESC) dr FROM employee e, department d WHERE e.departmentid = d.id) t WHERE t.dr <4;